Generating Shakespeare with Transformers
After building my custom tokenizer and exploring autograd from scratch, I was itching to tackle something bigger: implementing a full transformer architecture to generate Shakespeare-style text. This project combines everything I've learned about neural networks with the revolutionary "Attention Is All You Need" paper by Vaswani et al. - the work that launched the modern AI revolution.
I'll be honest - I've been fascinated by transformers ever since I first read about GPT-2 during my time at UC Berkeley. The idea that you could generate coherent text just by predicting the next character seemed like magic. I've been dabbling in training all kinds of transformers since then.
The Transformer Engine
From Attention Mechanisms to Elizabethan Poetry
The transformer architecture: where attention mechanisms meet language generation to create surprisingly coherent text.
What I Built
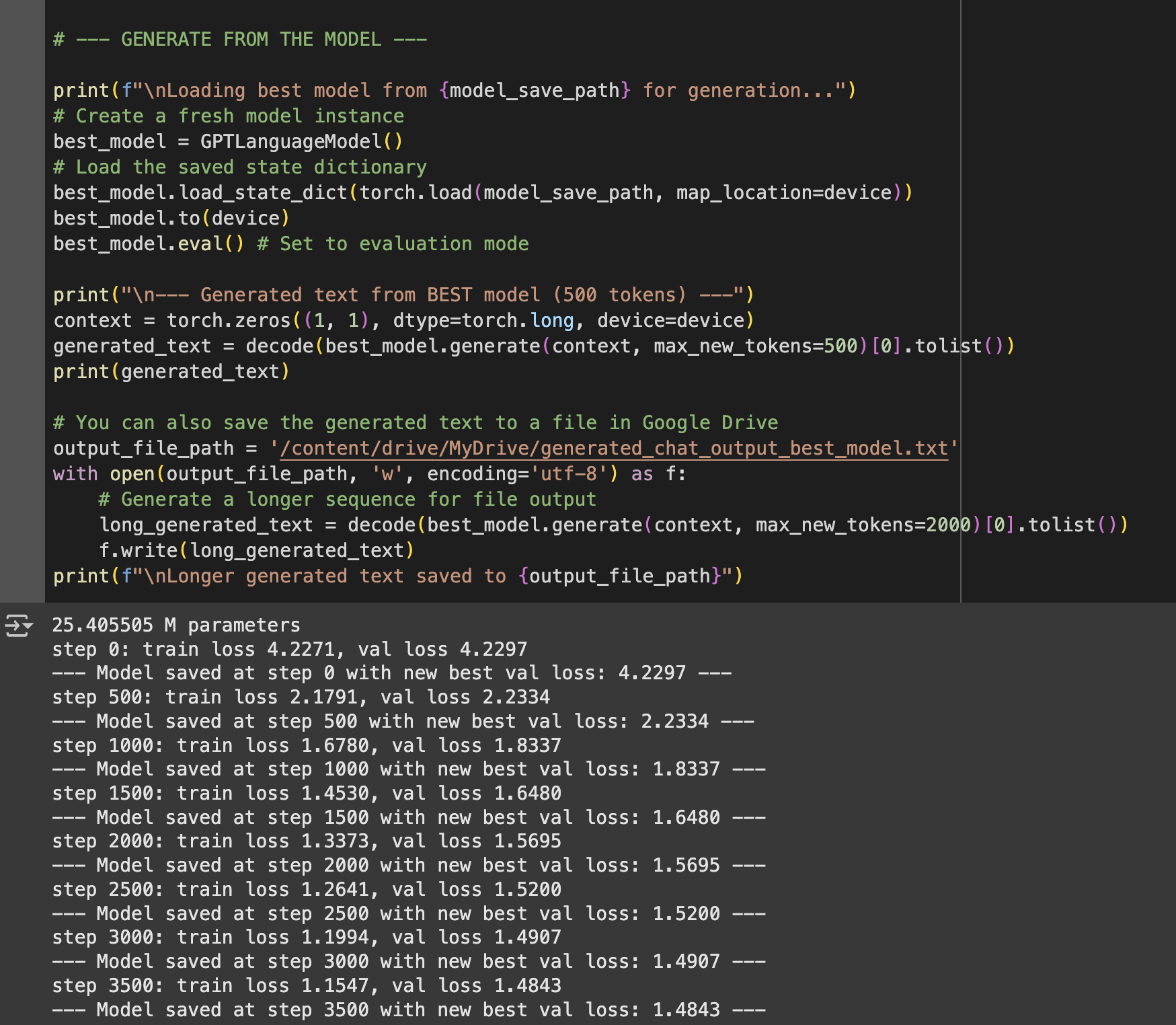
This project resulted in a complete decoder-only transformer implementation that generates Shakespeare-style text. I trained it on the classic tiny-shakespeare dataset using A100 GPUs (because let's be real, training transformers on my laptop would take forever). The model achieves impressive results with just 8 layers and 8 attention heads, generating surprisingly coherent Elizabethan prose.
Model Architecture
37.2M Parameters
8 layers × 8 attention heads
512 embedding dimensions
256 Context Length
Character-level tokenization
65 unique characters
Generated Shakespeare Sample
Loading generated text...
Model: 8-layer transformer with 8 attention heads (37.2M parameters)
Training: Character-level on tiny-shakespeare dataset
Context: 256 characters, trained for 5000 iterations
Technical Implementation
The complete implementation spans several key components, all built from scratch in PyTorch. I drew heavy inspiration from Andrej Karpathy's excellent nanoGPT repository, which provided invaluable guidance on transformer architecture and training best practices.
The complete code is in the Google Colab notebook below, with step-by-step explanations and room to experiment with different architectures and hyperparameters.
The core architecture in the "Attention Is All You Need" paper is surprisingly tractable to implement from scratch. Most of the complexity in modern LLMs is in the scale and training infrastructure, not the fundamental architecture.